2019/March Braindump2go 70-767 Exam Dumps with PDF and VCE New Updated Today! Following are some new 70-767 Real Exam Questions:
2019/March Braindump2go 70-767 Exam Dumps with PDF and VCE New Updated Today! Following are some new 70-767 Real Exam Questions:
2019/March Braindump2go 70-767 Exam Dumps with PDF and VCE New Updated Today! Following are some new 70-767 Real Exam Questions:
2019/March Braindump2go 70-767 Exam Dumps with PDF and VCE New Updated Today! Following are some new 70-767 Real Exam Questions:
2018/October Braindump2go 70-767 Exam Dumps with PDF and VCE New Updated Today! Folliwing are some new 70-767 Real Exam Questions:
2018 May New Microsoft 70-767 Exam Dumps with PDF and VCE Just Updated Today! Following are some new 70-767 Real Exam Questions:
2018 May New Microsoft 70-767 Exam Dumps with PDF and VCE Just Updated Today! Following are some new 70-767 Real Exam Questions:
2018 May New Microsoft 70-767 Exam Dumps with PDF and VCE Just Updated Today! Following are some new 70-767 Real Exam Questions:
2018 May New Microsoft 70-767 Exam Dumps with PDF and VCE Just Updated Today! Following are some new 70-767 Real Exam Questions:
2018 March New Microsoft 70-697 Exam Dumps with PDF and VCE Free Updated Today! Following are some new 70-697 Real Exam Questions:
1.|2018 Latest 70-697 Exam Dumps (PDF & VCE) 287Q&As Download:
https://www.braindump2go.com/70-767.html
2.|2018 Latest 70-697 Exam Questions & Answers Download:
https://drive.google.com/drive/folders/0B75b5xYLjSSNN1RSdlN6Z0VwRjg?usp=sharing
QUESTION 281
Hotspot Question
You deploy a Microsoft Azure SQL Data Warehouse instance. The instance must be available eight hours each day.
You need to pause Azure resources when they are not in use to reduce costs.
What will be the impact of pausing resources? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
To save costs, you can pause and resume compute resources on-demand. For example, if you won’t be using the database during the night and on weekends, you can pause it during those times, and resume it during the day. You won’t be charged for DWUs while the database is paused.
When you pause a database:
Compute and memory resources are returned to the pool of available resources in the data center
Data Warehouse Unit (DWU) costs are zero for the duration of the pause. Data storage is not affected and your data stays intact. SQL Data Warehouse cancels all running or queued operations.
When you resume a database:
SQL Data Warehouse acquires compute and memory resources for your DWU setting.
Compute charges for your DWUs resume.
Your data will be available.
You will need to restart your workload queries.
References: https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-manage-compute-rest-api
QUESTION 282
Drag and Drop Question
You have a data warehouse.
You need to move a table named Fact.ErrorLog to a new filegroup named LowCost.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Answer:
Explanation:
Step 1: Add a filegroup named LowCost to the database.
First create a new filegroup.
Step 2:
The next stage is to go to the `Files’ page in the same Properties window and add a file to the filegroup (a filegroup always contains one or more files)
Step 3:
To move a table to a different filegroup involves moving the table’s clustered index to the new filegroup. While this may seem strange at first this is not that surprising when you remember that the leaf level of the clustered index actually contains the table data. Moving the clustered index can be done in a single statement using the DROP_EXISTING clause as follows (using one of the AdventureWorks2008R2 tables as an example) :
CREATE UNIQUE CLUSTERED INDEX PK_Department_DepartmentID ON HumanResources.Department(DepartmentID)
WITH (DROP_EXISTING=ON,ONLINE=ON) ON SECONDARY
This recreates the same index but on the SECONDARY filegroup.
References:
http://www.sqlmatters.com/Articles/Moving%20a%20Table%20to%20a%20Different%20Filegroup.aspx
QUESTION 283
Hotspot Question
You have a Microsoft SQL Server Data Warehouse instance that uses SQL Server Analysis Services (SSAS). The instance has a cube containing data from an on-premises SQL Server instance. A measure named Measure1 is configured to calculate the average of a column.
You plan to change Measure1 to a full additive measure and create a new measure named Measure2 that evaluates data based on the first populated row.
You need to configure the measures.
What should you do? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Box 1:
The default setting is SUM (fully additive).
Box 2:
FirstNonEmpty: The member value is evaluated as the value of its first child along the time dimension that contains data.
References: https://docs.microsoft.com/en-us/sql/analysis-services/multidimensional-models/define-semiadditive-behavior
QUESTION 284
Drag and Drop Question
You administer a Microsoft SQL Server Master Data Services (MDS) model. All model entity members have passed validation.
The current model version should be committed to form a record of master data that can be audited and create a new version to allow the ongoing management of the master data.
You lock the current version. You need to manage the model versions.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area, and arrange them in the correct order.
Answer:
Explanation:
Box 1: Validate the current version.
In Master Data Services, validate a version to apply business rules to all members in the model version.
You can validate a version after it has been locked.
Box 2: Commit the current version.
In Master Data Services, commit a version of a model to prevent changes to the model’s members and their attributes. Committed versions cannot be unlocked.
Prerequisites:
Box 3: Create a copy of the current version.
In Master Data Services, copy a version of the model to create a new version of it.
QUESTION 285
Hotspot Question
You manage an inventory system that has a table named Products. The Products table has several hundred columns.
You generate a report that relates two columns named ProductReference and ProductName from the Products table. The result is sorted by a column named QuantityInStock from largest to smallest.
You need to create an index that the report can use.
How should you complete the Transact-SQL statement? To answer, select the appropriate Transact-SQL segments in the answer area.
Answer:
QUESTION 286
Hotspot Question
You have the Microsoft SQL Server Integration Services (SSIS) package shown in the Control flow exhibit. (Click the Exhibit button.)
The package iterates over 100 files in a local folder. For each iteration, the package increments a variable named loop as shown in the Expression task exhibit. (Click the Exhibit button) and then imports a file. The initial value of the variable loop is 0.
You suspect that there may be an issue with the variable value during the loop. You define a breakpoint on the Expression task as shown in the BreakPoint exhibit. (Click the Exhibit button.)
You need to check the value of the loop variable value.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Break condition: When the task or container receives the OnPreExecute event. Called when a task is about to execute. This event is raised by a task or a container immediately before it runs.
The loop variable does not reset.
With the debugger, you can break, or suspend, execution of your program to examine your code, evaluate and edit variables in your program, etc.
QUESTION 287
Hotspot Question
You have a database named DB1. You create a Microsoft SQL Server Integration Services (SSIS) package that incrementally imports data from a table named Customers. The package uses an OLE DB data source for connections to DB1. The package defines the following variables.
To support incremental data loading, you create a table by running the following Transact- SQL segment:
You need to create a DML statements that updates the LastKeyByTable table.
How should you complete the Transact-SQL statement? To answer, select the appropriate Transact-SQL segments in the dialog box in the answer area.
Answer:
!!!RECOMMEND!!!
1.|2018 Latest 70-697 Exam Dumps (PDF & VCE) 287Q&As Download:
https://www.braindump2go.com/70-767.html
2.|2018 Latest 70-697 Study Guide Video:
https://youtu.be/di0FBePt_-w
2018 March New Microsoft 70-697 Exam Dumps with PDF and VCE Free Updated Today! Following are some new 70-697 Real Exam Questions:
1.|2018 Latest 70-697 Exam Dumps (PDF & VCE) 287Q&As Download:
https://www.braindump2go.com/70-767.html
2.|2018 Latest 70-697 Exam Questions & Answers Download:
https://drive.google.com/drive/folders/0B75b5xYLjSSNN1RSdlN6Z0VwRjg?usp=sharing
QUESTION 270
Hotspot Question
You have a series of analytic data models and reports that provide insights into the participation rates for sports at different schools. Users enter information about sports and participants into a client application. The application stores this transactional data in a Microsoft SQL Server database. A SQL Server Integration Services (SSIS) package loads the data into the models.
When users enter data, they do not consistently apply the correct names for the sports. The following table shows examples of the data entry issues.
You need to create a new knowledge base to improve the quality of the sport name data.
How should you configure the knowledge base? To answer, select the appropriate options in the dialog box in the answer area.
Answer:
Explanation:
Spot 1: Create Knowledge base from: None
Select None if you do not want to base the new knowledge base on an existing knowledge base or data file.
QUESTION 271
Drag and Drop Question
You have a series of analytic data models and reports that provide insights into the participation rates for sports at different schools. Users enter information about sports and participants into a client application. The application stores this transactional data in a Microsoft SQL Server database. A SQL Server Integration Services (SSIS) package loads the data into the models.
When users enter data, they do not consistently apply the correct names for the sports. The following table shows examples of the data entry issues.
You need to improve the quality of the data.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Answer:
Explanation:
https://docs.microsoft.com/en-us/sql/data-quality-services/perform-knowledge-discovery
QUESTION 272
Drag and Drop Question
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have a Microsoft SQL Server data warehouse instance that supports several client applications.
The data warehouse includes the following tables: Dimension.SalesTerritory, Dimension.Customer, Dimension.Date, Fact.Ticket, and Fact.Order.
The Dimension.SalesTerritory and Dimension.Customer tables are frequently updated.
The Fact.Order table is optimized for weekly reporting, but the company wants to change it daily. The Fact.Order table is loaded by using an ETL process. Indexes have been added to the table over time, but the presence of these indexes slows data loading.
All data in the data warehouse is stored on a shared SAN. All tables are in a database named DB1. You have a second database named DB2 that contains copies of production data for a development environment. The data warehouse has grown and the cost of storage has increased. Data older than one year is accessed infrequently and is considered historical.
You have the following requirements:
– Implement table partitioning to improve the manageability of the data warehouse and to avoid the need to repopulate all transactional data each night.
– Use a partitioning strategy that is as granular as possible.
– Partition the Fact.Order table and retain a total of seven years of data.
– Partition the Fact.Ticket table and retain seven years of data. At the end of each month, the partition structure must apply a sliding window strategy to ensure that a new partition is available for the upcoming month, and that the oldest month of data is archived and removed.
– Optimize data loading for the Dimension.SalesTerritory, Dimension.Customer, and Dimension.Date tables.
– Incrementally load all tables in the database and ensure that all incremental changes are processed.
– Maximize the performance during the data loading process for the Fact.Order partition.
– Ensure that historical data remains online and available for querying.
– Reduce ongoing storage costs while maintaining query performance for current data.
You are not permitted to make changes to the client applications.
You need to configure the Fact.Order table.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Answer:
Explanation:
From scenario: Partition the Fact.Order table and retain a total of seven years of data. Maximize the performance during the data loading process for the Fact.Order partition.
Step 1: Create a partition function.
Using CREATE PARTITION FUNCTION is the first step in creating a partitioned table or index.
Step 2: Create a partition scheme based on the partition function. To migrate SQL Server partition definitions to SQL Data Warehouse simply:
Step 3: Execute an ALTER TABLE command to specify the partition function.
References: https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-tables-partition
QUESTION 273
Hotspot Question
You manage a data warehouse in a Microsoft SQL Server instance. Company employee information is imported from the human resources system to a table named Employee in the data warehouse instance. The Employee table was created by running the query shown in the Employee Schema exhibit. (Click the Exhibit button.)
The personal identification number is stored in a column named EmployeeSSN. All values in the EmployeeSSN column must be unique.
When importing employee data, you receive the error message shown in the SQL Error exhibit. (Click the Exhibit button.).
You determine that the Transact-SQL statement shown in the Data Load exhibit in the cause of the error. (Click the Exhibit button.)
You remove the constraint on the EmployeeSSN column. You need to ensure that values in the EmployeeSSN column are unique.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
With the ANSI standards SQL:92, SQL:1999 and SQL:2003, an UNIQUE constraint must disallow duplicate non-NULL values but accept multiple NULL values.
In the Microsoft world of SQL Server however, a single NULL is allowed but multiple NULLs are not.
From SQL Server 2008, you can define a unique filtered index based on a predicate that excludes NULLs.
References: https://stackoverflow.com/questions/767657/how-do-i-create-a-unique-constraint-that-also-allows-nulls
QUESTION 274
Hotspot Question
Your company has a Microsoft SQL Server data warehouse instance. The human resources department assigns all employees a unique identifier. You plan to store this identifier in a new table named Employee.
You create a new dimension to store information about employees by running the following Transact-SQL statement:
You have not added data to the dimension yet. You need to modify the dimension to implement a new column named [EmployeeKey]. The new column must use unique values.
How should you complete the Transact-SQL statements? To answer, select the appropriate Transact-SQL segments in the answer area.
Answer:
QUESTION 275
Drag and Drop Question
You have a Microsoft SQL Server Integration Services (SSIS) package that loads data into a data warehouse each night from a transactional system. The package also loads data from a set of Comma-Separated Values (CSV) files that are provided by your company’s finance department.
The SSIS package processes each CSV file in a folder. The package reads the file name for the current file into a variable and uses that value to write a log entry to a database table.
You need to debug the package and determine the value of the variable before each file is processed.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Answer:
Explanation:
You debug control flows.
The Foreach Loop container is used for looping through a group of files. Put the breakpoint on it.
The Locals window displays information about the local expressions in the current scope of the Transact-SQL debugger.
References: https://docs.microsoft.com/en-us/sql/integration-services/troubleshooting/debugging-control-flow
http://blog.pragmaticworks.com/looping-through-a-result-set-with-the-foreach-loop
QUESTION 276
Hotspot Question
You create a Microsoft SQL Server Integration Services (SSIS) package as shown in the SSIS Package exhibit. (Click the Exhibit button.)
The package uses data from the Products table and the Prices table. Properties of the Prices source are shown in the OLE DB Source Editor exhibit (Click the Exhibit Button.) and the Advanced Editor for Prices exhibit (Click the Exhibit button.)
You join the Products and Prices tables by using the ReferenceNr column.
You need to resolve the error with the package.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
There are two important sort properties that must be set for the source or upstream transformation that supplies data to the Merge and Merge Join transformations:
The Merge Join Transformation requires sorted data for its inputs.
If you do not use a Sort transformation to sort the data, you must set these sort properties manually on the source or the upstream transformation.
References: https://docs.microsoft.com/en-us/sql/integration-services/data-flow/transformations/sort-data-for-the-merge-and-merge-join-transformations
QUESTION 277
Drag and Drop Question
You deploy a Microsoft Server database that contains a staging table named EmailAddress_Import. Each night, a bulk process will import customer information from an external database, cleanse the data, and then insert it into the EmailAddress table. Both tables contain a column named EmailAddressValue that stores the email address.
You need to implement the logic to meet the following requirements:
Email addresses that are present in the EmailAddress_Import table but not in the EmailAddress table must be inserted into the EmailAddress table. Email addresses that are not in the EmailAddress_Import but are present in the EmailAddress table must be deleted from the EmailAddress table.
How should you complete the Transact-SQL statement? To answer, drag the appropriate Transact-SQL segments to the correct locations. Each Transact-SQL segment may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
Answer:
Explanation:
Box 1: EmailAddress
The EmailAddress table is the target.
Box 2: EmailAddress_import
The EmailAddress_import table is the source.
Box 3: NOT MATCHED BY TARGET
Box 4: NOT MATCHED BY SOURCE
References: https://docs.microsoft.com/en-us/sql/t-sql/statements/merge-transact-sql
QUESTION 278
Drag and Drop Question
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have a Microsoft SQL Server data warehouse instance that supports several client applications.
The data warehouse includes the following tables: Dimension.SalesTerritory, Dimension.Customer, Dimension.Date, Fact.Ticket, and Fact.Order. The Dimension.SalesTerritory and Dimension.Customer tables are frequently updated. The Fact.Order table is optimized for weekly reporting, but the company wants to change it daily. The Fact.Order table is loaded by using an ETL process. Indexes have been added to the table over time, but the presence of these indexes slows data loading.
All data in the data warehouse is stored on a shared SAN. All tables are in a database named DB1. You have a second database named DB2 that contains copies of production data for a development environment. The data warehouse has grown and the cost of storage has increased. Data older than one year is accessed infrequently and is considered historical.
You have the following requirements:
Implement table partitioning to improve the manageability of the data warehouse and to avoid the need to repopulate all transactional data each night. Use a partitioning strategy that is as granular as possible.
Partition the Fact.Order table and retain a total of seven years of data.
Partition the Fact.Ticket table and retain seven years of data. At the end of each month, the partition structure must apply a sliding window strategy to ensure that a new partition is available for the upcoming month, and that the oldest month of data is archived and removed.
Optimize data loading for the Dimension.SalesTerritory, Dimension.Customer, and Dimension.Date tables.
Incrementally load all tables in the database and ensure that all incremental changes are processed.
Maximize the performance during the data loading process for the Fact.Order partition.
Ensure that historical data remains online and available for querying.
Reduce ongoing storage costs while maintaining query performance for current data.
You are not permitted to make changes to the client applications.
You need to implement partitioning for the Fact.Ticket table.
Which three actions should you perform in sequence? To answer, drag the appropriate actions to the correct locations. Each action may be used once, more than once or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: More than one combination of answer choices is correct. You will receive credit for any of the correct combinations you select.
Answer:
Explanation:
From scenario: – Partition the Fact.Ticket table and retain seven years of data. At the end of each month, the partition structure must apply a sliding window strategy to ensure that a new partition is available for the upcoming month, and that the oldest month of data is archived and removed.
The detailed steps for the recurring partition maintenance tasks are:
References: https://docs.microsoft.com/en-us/sql/relational-databases/tables/manage-retention-of-historical-data-in-system-versioned-temporal-tables
QUESTION 279
Drag and Drop Question
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have a Microsoft SQL Server data warehouse instance that supports several client applications.
The data warehouse includes the following tables: Dimension.SalesTerritory, Dimension.Customer, Dimension.Date, Fact.Ticket, and Fact.Order. The Dimension.SalesTerritory and Dimension.Customer tables are frequently updated. The Fact.Order table is optimized for weekly reporting, but the company wants to change it daily. The Fact.Order table is loaded by using an ETL process. Indexes have been added to the table over time, but the presence of these indexes slows data loading.
All data in the data warehouse is stored on a shared SAN. All tables are in a database named DB1. You have a second database named DB2 that contains copies of production data for a development environment. The data warehouse has grown and the cost of storage has increased. Data older than one year is accessed infrequently and is considered historical.
You have the following requirements:
Implement table partitioning to improve the manageability of the data warehouse and to avoid the need to repopulate all transactional data each night. Use a partitioning strategy that is as granular as possible.
Partition the Fact.Order table and retain a total of seven years of data.
Partition the Fact.Ticket table and retain seven years of data. At the end of each month, the partition structure must apply a sliding window strategy to ensure that a new partition is available for the upcoming month, and that the oldest month of data is archived and removed.
Optimize data loading for the Dimension.SalesTerritory, Dimension.Customer, and Dimension.Date tables.
Incrementally load all tables in the database and ensure that all incremental changes are processed.
Maximize the performance during the data loading process for the Fact.Order partition.
Ensure that historical data remains online and available for querying.
Reduce ongoing storage costs while maintaining query performance for current data.
You are not permitted to make changes to the client applications.
You need to optimize data loading for the Dimension.Customer table.
Which three Transact-SQL segments should you use to develop the solution? To answer, move the appropriate Transact-SQL segments from the list of Transact-SQL segments to the answer area and arrange them in the correct order.
NOTE: You will not need all of the Transact-SQL segments.
Answer:
Explanation:
Step 1: USE DB1
From Scenario: All tables are in a database named DB1. You have a second database named DB2 that contains copies of production data for a development environment.
Step 2: EXEC sys.sp_cdc_enable_db
Before you can enable a table for change data capture, the database must be enabled. To enable the database, use the sys.sp_cdc_enable_db stored procedure.
sys.sp_cdc_enable_db has no parameters.
Step 3: EXEC sys.sp_cdc_enable_table
@source schema = N ‘schema’ etc.
Sys.sp_cdc_enable_table enables change data capture for the specified source table in the current database.
Partial syntax:
sys.sp_cdc_enable_table
[ @source_schema = ] ‘source_schema’,
[ @source_name = ] ‘source_name’ , [,[ @capture_instance = ] ‘capture_instance’ ] [,[ @supports_net_changes = ] supports_net_changes ] Etc.
References: https://docs.microsoft.com/en-us/sql/relational-databases/system-stored-procedures/sys-sp-cdc-enable-table-transact-sql
https://docs.microsoft.com/en-us/sql/relational-databases/system-stored-procedures/sys-sp-cdc-enable-db-transact-sql
QUESTION 280
Hotspot Question
You have a Microsoft SQL Server Integration Services (SSIS) package that contains a Data Flow task as shown in the Data Flow exhibit. (Click the Exhibit button.)
You install Data Quality Services (DQS) on the same server that hosts SSIS and deploy a knowledge base to manage customer email addresses. You add a DQS Cleansing transform to the Data Flow as shown in the Cleansing exhibit. (Click the Exhibit button.)
You create a Conditional Split transform as shown in the Splitter exhibit. (Click the Exhibit button.)
You need to split the output of the DQS Cleansing task to obtain only Correct values from the EmailAddress column.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
Answer:
Explanation:
The DQS Cleansing component takes input records, sends them to a DQS server, and gets them back corrected. The component can output not only the corrected data, but also additional columns that may be useful for you. For example – the status columns. There is one status column for each mapped field, and another one that aggregated the status for the whole record. This record status column can be very useful in some scenarios, especially when records are further processed in different ways depending on their status. Is such cases, it is recommended to use a Conditional Split component below the DQS Cleansing component, and configure it to split the records to groups based on the record status (or based on other columns such as specific field status).
References: https://blogs.msdn.microsoft.com/dqs/2011/07/18/using-the-ssis-dqs-cleansing-component/
!!!RECOMMEND!!!
1.|2018 Latest 70-697 Exam Dumps (PDF & VCE) 287Q&As Download:
https://www.braindump2go.com/70-767.html
2.|2018 Latest 70-697 Study Guide Video:
https://youtu.be/di0FBePt_-w
2018 March New Microsoft 70-697 Exam Dumps with PDF and VCE Free Updated Today! Following are some new 70-697 Real Exam Questions:
1.|2018 Latest 70-697 Exam Dumps (PDF & VCE) 287Q&As Download:
https://www.braindump2go.com/70-767.html
2.|2018 Latest 70-697 Exam Questions & Answers Download:
https://drive.google.com/drive/folders/0B75b5xYLjSSNN1RSdlN6Z0VwRjg?usp=sharing
QUESTION 270
Hotspot Question
You have a series of analytic data models and reports that provide insights into the participation rates for sports at different schools. Users enter information about sports and participants into a client application. The application stores this transactional data in a Microsoft SQL Server database. A SQL Server Integration Services (SSIS) package loads the data into the models.
When users enter data, they do not consistently apply the correct names for the sports. The following table shows examples of the data entry issues.
You need to create a new knowledge base to improve the quality of the sport name data.
How should you configure the knowledge base? To answer, select the appropriate options in the dialog box in the answer area.
Answer:
Explanation:
Spot 1: Create Knowledge base from: None
Select None if you do not want to base the new knowledge base on an existing knowledge base or data file.
QUESTION 271
Drag and Drop Question
You have a series of analytic data models and reports that provide insights into the participation rates for sports at different schools. Users enter information about sports and participants into a client application. The application stores this transactional data in a Microsoft SQL Server database. A SQL Server Integration Services (SSIS) package loads the data into the models.
When users enter data, they do not consistently apply the correct names for the sports. The following table shows examples of the data entry issues.
You need to improve the quality of the data.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Answer:
Explanation:
https://docs.microsoft.com/en-us/sql/data-quality-services/perform-knowledge-discovery
QUESTION 272
Drag and Drop Question
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have a Microsoft SQL Server data warehouse instance that supports several client applications.
The data warehouse includes the following tables: Dimension.SalesTerritory, Dimension.Customer, Dimension.Date, Fact.Ticket, and Fact.Order.
The Dimension.SalesTerritory and Dimension.Customer tables are frequently updated.
The Fact.Order table is optimized for weekly reporting, but the company wants to change it daily. The Fact.Order table is loaded by using an ETL process. Indexes have been added to the table over time, but the presence of these indexes slows data loading.
All data in the data warehouse is stored on a shared SAN. All tables are in a database named DB1. You have a second database named DB2 that contains copies of production data for a development environment. The data warehouse has grown and the cost of storage has increased. Data older than one year is accessed infrequently and is considered historical.
You have the following requirements:
– Implement table partitioning to improve the manageability of the data warehouse and to avoid the need to repopulate all transactional data each night.
– Use a partitioning strategy that is as granular as possible.
– Partition the Fact.Order table and retain a total of seven years of data.
– Partition the Fact.Ticket table and retain seven years of data. At the end of each month, the partition structure must apply a sliding window strategy to ensure that a new partition is available for the upcoming month, and that the oldest month of data is archived and removed.
– Optimize data loading for the Dimension.SalesTerritory, Dimension.Customer, and Dimension.Date tables.
– Incrementally load all tables in the database and ensure that all incremental changes are processed.
– Maximize the performance during the data loading process for the Fact.Order partition.
– Ensure that historical data remains online and available for querying.
– Reduce ongoing storage costs while maintaining query performance for current data.
You are not permitted to make changes to the client applications.
You need to configure the Fact.Order table.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Answer:
Explanation:
From scenario: Partition the Fact.Order table and retain a total of seven years of data. Maximize the performance during the data loading process for the Fact.Order partition.
Step 1: Create a partition function.
Using CREATE PARTITION FUNCTION is the first step in creating a partitioned table or index.
Step 2: Create a partition scheme based on the partition function. To migrate SQL Server partition definitions to SQL Data Warehouse simply:
Step 3: Execute an ALTER TABLE command to specify the partition function.
References: https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-tables-partition
QUESTION 273
Hotspot Question
You manage a data warehouse in a Microsoft SQL Server instance. Company employee information is imported from the human resources system to a table named Employee in the data warehouse instance. The Employee table was created by running the query shown in the Employee Schema exhibit. (Click the Exhibit button.)
The personal identification number is stored in a column named EmployeeSSN. All values in the EmployeeSSN column must be unique.
When importing employee data, you receive the error message shown in the SQL Error exhibit. (Click the Exhibit button.).
You determine that the Transact-SQL statement shown in the Data Load exhibit in the cause of the error. (Click the Exhibit button.)
You remove the constraint on the EmployeeSSN column. You need to ensure that values in the EmployeeSSN column are unique.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
With the ANSI standards SQL:92, SQL:1999 and SQL:2003, an UNIQUE constraint must disallow duplicate non-NULL values but accept multiple NULL values.
In the Microsoft world of SQL Server however, a single NULL is allowed but multiple NULLs are not.
From SQL Server 2008, you can define a unique filtered index based on a predicate that excludes NULLs.
References: https://stackoverflow.com/questions/767657/how-do-i-create-a-unique-constraint-that-also-allows-nulls
QUESTION 274
Hotspot Question
Your company has a Microsoft SQL Server data warehouse instance. The human resources department assigns all employees a unique identifier. You plan to store this identifier in a new table named Employee.
You create a new dimension to store information about employees by running the following Transact-SQL statement:
You have not added data to the dimension yet. You need to modify the dimension to implement a new column named [EmployeeKey]. The new column must use unique values.
How should you complete the Transact-SQL statements? To answer, select the appropriate Transact-SQL segments in the answer area.
Answer:
QUESTION 275
Drag and Drop Question
You have a Microsoft SQL Server Integration Services (SSIS) package that loads data into a data warehouse each night from a transactional system. The package also loads data from a set of Comma-Separated Values (CSV) files that are provided by your company’s finance department.
The SSIS package processes each CSV file in a folder. The package reads the file name for the current file into a variable and uses that value to write a log entry to a database table.
You need to debug the package and determine the value of the variable before each file is processed.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Answer:
Explanation:
You debug control flows.
The Foreach Loop container is used for looping through a group of files. Put the breakpoint on it.
The Locals window displays information about the local expressions in the current scope of the Transact-SQL debugger.
References: https://docs.microsoft.com/en-us/sql/integration-services/troubleshooting/debugging-control-flow
http://blog.pragmaticworks.com/looping-through-a-result-set-with-the-foreach-loop
QUESTION 276
Hotspot Question
You create a Microsoft SQL Server Integration Services (SSIS) package as shown in the SSIS Package exhibit. (Click the Exhibit button.)
The package uses data from the Products table and the Prices table. Properties of the Prices source are shown in the OLE DB Source Editor exhibit (Click the Exhibit Button.) and the Advanced Editor for Prices exhibit (Click the Exhibit button.)
You join the Products and Prices tables by using the ReferenceNr column.
You need to resolve the error with the package.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
There are two important sort properties that must be set for the source or upstream transformation that supplies data to the Merge and Merge Join transformations:
The Merge Join Transformation requires sorted data for its inputs.
If you do not use a Sort transformation to sort the data, you must set these sort properties manually on the source or the upstream transformation.
References: https://docs.microsoft.com/en-us/sql/integration-services/data-flow/transformations/sort-data-for-the-merge-and-merge-join-transformations
QUESTION 277
Drag and Drop Question
You deploy a Microsoft Server database that contains a staging table named EmailAddress_Import. Each night, a bulk process will import customer information from an external database, cleanse the data, and then insert it into the EmailAddress table. Both tables contain a column named EmailAddressValue that stores the email address.
You need to implement the logic to meet the following requirements:
Email addresses that are present in the EmailAddress_Import table but not in the EmailAddress table must be inserted into the EmailAddress table. Email addresses that are not in the EmailAddress_Import but are present in the EmailAddress table must be deleted from the EmailAddress table.
How should you complete the Transact-SQL statement? To answer, drag the appropriate Transact-SQL segments to the correct locations. Each Transact-SQL segment may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
Answer:
Explanation:
Box 1: EmailAddress
The EmailAddress table is the target.
Box 2: EmailAddress_import
The EmailAddress_import table is the source.
Box 3: NOT MATCHED BY TARGET
Box 4: NOT MATCHED BY SOURCE
References: https://docs.microsoft.com/en-us/sql/t-sql/statements/merge-transact-sql
QUESTION 278
Drag and Drop Question
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have a Microsoft SQL Server data warehouse instance that supports several client applications.
The data warehouse includes the following tables: Dimension.SalesTerritory, Dimension.Customer, Dimension.Date, Fact.Ticket, and Fact.Order. The Dimension.SalesTerritory and Dimension.Customer tables are frequently updated. The Fact.Order table is optimized for weekly reporting, but the company wants to change it daily. The Fact.Order table is loaded by using an ETL process. Indexes have been added to the table over time, but the presence of these indexes slows data loading.
All data in the data warehouse is stored on a shared SAN. All tables are in a database named DB1. You have a second database named DB2 that contains copies of production data for a development environment. The data warehouse has grown and the cost of storage has increased. Data older than one year is accessed infrequently and is considered historical.
You have the following requirements:
Implement table partitioning to improve the manageability of the data warehouse and to avoid the need to repopulate all transactional data each night. Use a partitioning strategy that is as granular as possible.
Partition the Fact.Order table and retain a total of seven years of data.
Partition the Fact.Ticket table and retain seven years of data. At the end of each month, the partition structure must apply a sliding window strategy to ensure that a new partition is available for the upcoming month, and that the oldest month of data is archived and removed.
Optimize data loading for the Dimension.SalesTerritory, Dimension.Customer, and Dimension.Date tables.
Incrementally load all tables in the database and ensure that all incremental changes are processed.
Maximize the performance during the data loading process for the Fact.Order partition.
Ensure that historical data remains online and available for querying.
Reduce ongoing storage costs while maintaining query performance for current data.
You are not permitted to make changes to the client applications.
You need to implement partitioning for the Fact.Ticket table.
Which three actions should you perform in sequence? To answer, drag the appropriate actions to the correct locations. Each action may be used once, more than once or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: More than one combination of answer choices is correct. You will receive credit for any of the correct combinations you select.
Answer:
Explanation:
From scenario: – Partition the Fact.Ticket table and retain seven years of data. At the end of each month, the partition structure must apply a sliding window strategy to ensure that a new partition is available for the upcoming month, and that the oldest month of data is archived and removed.
The detailed steps for the recurring partition maintenance tasks are:
References: https://docs.microsoft.com/en-us/sql/relational-databases/tables/manage-retention-of-historical-data-in-system-versioned-temporal-tables
QUESTION 279
Drag and Drop Question
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have a Microsoft SQL Server data warehouse instance that supports several client applications.
The data warehouse includes the following tables: Dimension.SalesTerritory, Dimension.Customer, Dimension.Date, Fact.Ticket, and Fact.Order. The Dimension.SalesTerritory and Dimension.Customer tables are frequently updated. The Fact.Order table is optimized for weekly reporting, but the company wants to change it daily. The Fact.Order table is loaded by using an ETL process. Indexes have been added to the table over time, but the presence of these indexes slows data loading.
All data in the data warehouse is stored on a shared SAN. All tables are in a database named DB1. You have a second database named DB2 that contains copies of production data for a development environment. The data warehouse has grown and the cost of storage has increased. Data older than one year is accessed infrequently and is considered historical.
You have the following requirements:
Implement table partitioning to improve the manageability of the data warehouse and to avoid the need to repopulate all transactional data each night. Use a partitioning strategy that is as granular as possible.
Partition the Fact.Order table and retain a total of seven years of data.
Partition the Fact.Ticket table and retain seven years of data. At the end of each month, the partition structure must apply a sliding window strategy to ensure that a new partition is available for the upcoming month, and that the oldest month of data is archived and removed.
Optimize data loading for the Dimension.SalesTerritory, Dimension.Customer, and Dimension.Date tables.
Incrementally load all tables in the database and ensure that all incremental changes are processed.
Maximize the performance during the data loading process for the Fact.Order partition.
Ensure that historical data remains online and available for querying.
Reduce ongoing storage costs while maintaining query performance for current data.
You are not permitted to make changes to the client applications.
You need to optimize data loading for the Dimension.Customer table.
Which three Transact-SQL segments should you use to develop the solution? To answer, move the appropriate Transact-SQL segments from the list of Transact-SQL segments to the answer area and arrange them in the correct order.
NOTE: You will not need all of the Transact-SQL segments.
Answer:
Explanation:
Step 1: USE DB1
From Scenario: All tables are in a database named DB1. You have a second database named DB2 that contains copies of production data for a development environment.
Step 2: EXEC sys.sp_cdc_enable_db
Before you can enable a table for change data capture, the database must be enabled. To enable the database, use the sys.sp_cdc_enable_db stored procedure.
sys.sp_cdc_enable_db has no parameters.
Step 3: EXEC sys.sp_cdc_enable_table
@source schema = N ‘schema’ etc.
Sys.sp_cdc_enable_table enables change data capture for the specified source table in the current database.
Partial syntax:
sys.sp_cdc_enable_table
[ @source_schema = ] ‘source_schema’,
[ @source_name = ] ‘source_name’ , [,[ @capture_instance = ] ‘capture_instance’ ] [,[ @supports_net_changes = ] supports_net_changes ] Etc.
References: https://docs.microsoft.com/en-us/sql/relational-databases/system-stored-procedures/sys-sp-cdc-enable-table-transact-sql
https://docs.microsoft.com/en-us/sql/relational-databases/system-stored-procedures/sys-sp-cdc-enable-db-transact-sql
QUESTION 280
Hotspot Question
You have a Microsoft SQL Server Integration Services (SSIS) package that contains a Data Flow task as shown in the Data Flow exhibit. (Click the Exhibit button.)
You install Data Quality Services (DQS) on the same server that hosts SSIS and deploy a knowledge base to manage customer email addresses. You add a DQS Cleansing transform to the Data Flow as shown in the Cleansing exhibit. (Click the Exhibit button.)
You create a Conditional Split transform as shown in the Splitter exhibit. (Click the Exhibit button.)
You need to split the output of the DQS Cleansing task to obtain only Correct values from the EmailAddress column.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
Answer:
Explanation:
The DQS Cleansing component takes input records, sends them to a DQS server, and gets them back corrected. The component can output not only the corrected data, but also additional columns that may be useful for you. For example – the status columns. There is one status column for each mapped field, and another one that aggregated the status for the whole record. This record status column can be very useful in some scenarios, especially when records are further processed in different ways depending on their status. Is such cases, it is recommended to use a Conditional Split component below the DQS Cleansing component, and configure it to split the records to groups based on the record status (or based on other columns such as specific field status).
References: https://blogs.msdn.microsoft.com/dqs/2011/07/18/using-the-ssis-dqs-cleansing-component/
!!!RECOMMEND!!!
1.|2018 Latest 70-697 Exam Dumps (PDF & VCE) 287Q&As Download:
https://www.braindump2go.com/70-767.html
2.|2018 Latest 70-697 Study Guide Video:
https://youtu.be/di0FBePt_-w
2018 March New Microsoft 70-697 Exam Dumps with PDF and VCE Free Updated Today! Following are some new 70-697 Real Exam Questions:
1.|2018 Latest 70-697 Exam Dumps (PDF & VCE) 287Q&As Download:
https://www.braindump2go.com/70-767.html
2.|2018 Latest 70-697 Exam Questions & Answers Download:
https://drive.google.com/drive/folders/0B75b5xYLjSSNN1RSdlN6Z0VwRjg?usp=sharing
QUESTION 259
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this sections, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have the following line-of-business solutions:
ERP system
Online WebStore
Partner extranet
One or more Microsoft SQL Server instances support each solution. Each solution has its own product catalog. You have an additional server that hosts SQL Server Integration Services (SSIS) and a data warehouse. You populate the data warehouse with data from each of the line-of-business solutions. The data warehouse does not store primary key values from the individual source tables.
The database for each solution has a table named Products that stored product information. The Products table in each database uses a separate and unique key for product records. Each table shares a column named ReferenceNr between the databases. This column is used to create queries that involve more than once solution.
You need to load data from the individual solutions into the data warehouse nightly. The following requirements must be met:
If a change is made to the ReferenceNr column in any of the sources, set the value of IsDisabled to True and create a new row in the Products table.
If a row is deleted in any of the sources, set the value of IsDisabled to True in the data warehouse.
Solution: Perform the following actions:
Enable the Change Tracking for the Product table in the source databases.
Query the cdc.fn_cdc_get_all_changes_capture_dbo_products function from the sources for updated rows.
Set the IsDisabled column to True for rows with the old ReferenceNr value.
Create a new row in the data warehouse Products table with the new ReferenceNr value.
Does the solution meet the goal?
A. Yes
B. No
Answer: B
Explanation:
We must also handle the deleted rows, not just the updated rows.
References: https://solutioncenter.apexsql.com/enable-use-sql-server-change-data-capture/
QUESTION 260
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this sections, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
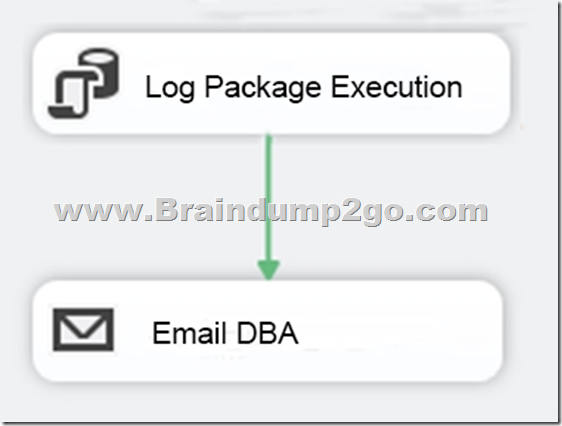
You are developing a Microsoft SQL Server Integration Services (SSIS) projects. The project consists of several packages that load data warehouse tables.
You need to extend the control flow design for each package to use the following control flow while minimizing development efforts and maintenance:
Solution: You add the control flow to an ASP.NET assembly. You add a script task that references this assembly to each data warehouse load package.
Does the solution meet the goal?
A. Yes
B. No
Answer: B
Explanation:
A package consists of a control flow and, optionally, one or more data flows. You create the control flow in a package by using the Control Flow tab in SSIS Designer.
References: https://docs.microsoft.com/en-us/sql/integration-services/control-flow/control-flow
QUESTION 261
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this sections, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a data warehouse that stores information about products, sales, and orders for a manufacturing company. The instance contains a database that has two tables named SalesOrderHeader and SalesOrderDetail. SalesOrderHeader has 500,000 rows and SalesOrderDetail has 3,000,000 rows.
Users report performance degradation when they run the following stored procedure:
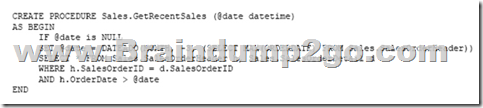
You need to optimize performance.
Solution: You run the following Transact-SQL statement:
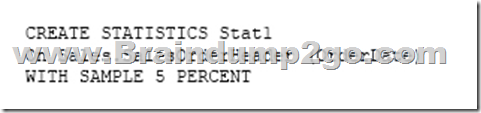
Does the solution meet the goal?
A. Yes
B. No
Answer: B
Explanation:
Microsoft recommend against specifying 0 PERCENT or 0 ROWS in a CREATE STATISTICS..WITH SAMPLE statement. When 0 PERCENT or ROWS is specified, the statistics object is created but does not contain statistics data.
References: https://docs.microsoft.com/en-us/sql/t-sql/statements/create-statistics-transact-sql
QUESTION 262
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this sections, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are developing a Microsoft SQL Server Integration Services (SSIS) projects. The project consists of several packages that load data warehouse tables.
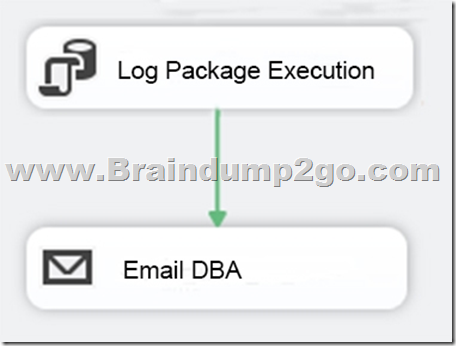
You need to extend the control flow design for each package to use the following control flow while minimizing development efforts and maintenance:
Solution: You add the control flow to a control flow package part.
You add an instance of the control flow package part to each data warehouse load package.
Does the solution meet the goal?
A. Yes
B. No
Answer: A
Explanation:
A package consists of a control flow and, optionally, one or more data flows.
You create the control flow in a package by using the Control Flow tab in SSIS Designer.
References: https://docs.microsoft.com/en-us/sql/integration-services/control-flow/control-flow
QUESTION 263
You have a data quality project that focuses on the Products catalog for the company. The data includes a product reference number.
The product reference should use the following format:
Two letters followed by an asterisk and then four or five numbers. An example of a valid number is XX*55522.
Any reference number that does not conform to the format must be rejected during the data cleansing.
You need to add a Data Quality Services (DQS) domain rule in the Products domain.
Which rule should you use?
A. value matches pattern ZA*9876[5]
B. value matches pattern AZ[*]1234[5]
C. value matches regular expression AZ[*]1234[5] D. value matches pattern [a-zA-Z][a-zA-Z]*[0-9][0-9] [0-9][0-9] [0-9]?
Answer: A
Explanation:
For a pattern matching rule:
Any letter (A…Z) can be used as a pattern for any letter; case insensitive Any digit (0…9) can be used as a pattern for any digit Any special character, except a letter or a digit, can be used as a pattern for itself Brackets, [], define optional matching
Example: ABC:0000
This rule implies that the data will contain three parts: any three letters followed by a colon
(:), which is again followed by any four digits.
QUESTION 264
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this sections, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Microsoft Azure SQL Data Warehouse instance that must be available six months a day for reporting.
You need to pause the compute resources when the instance is not being used.
Solution: You use SQL Server Management Studio (SSMS).
Does the solution meet the goal?
A. Yes
B. No
Answer: B
Explanation:
To pause a SQL Data Warehouse database, use any of these individual methods.
Pause compute with Azure portal
Pause compute with PowerShell
Pause compute with REST APIs
References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-manage-compute-overview
QUESTION 265
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You are a database administrator for an e-commerce company that runs an online store. The company has the databases described in the following table.

Each day, data from the table OnlineOrder in DB2 must be exported by partition. The tables must not be locked during the process.
You need to write a Microsoft SQL Server Integration Services (SSIS) package that performs the data export.
What should you use?
A. Lookup transformation
B. Merge transformation
C. Merge Join transformation
D. MERGE statement
E. Union All transformation
F. Balanced Data Distributor transformation
G. Sequential container
H. Foreach Loop container
Answer: E
Explanation:
The Union All transformation combines multiple inputs into one output. For example, the outputs from five different Flat File sources can be inputs to the Union All transformation and combined into one output.
References: https://docs.microsoft.com/en-us/sql/integration-services/data-flow/transformations/union-all-transformation
QUESTION 266
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You are a database administrator for an e-commerce company that runs an online store. The company has the databases described in the following table.

Product prices are updated and are stored in a table named Products on DB1. The Products table is deleted and refreshed each night from MDS by using a Microsoft SQL Server Integration Services (SSIS) package. None of the data sources are sorted.
You need to update the SSIS package to add current prices to the Products table.
What should you use?
A. Lookup transformation
B. Merge transformation
C. Merge Join transformation
D. MERGE statement
E. Union All transformation
F. Balanced Data Distributor transformation
G. Sequential container
H. Foreach Loop container
Answer: D
Explanation:
In the current release of SQL Server Integration Services, the SQL statement in an Execute SQL task can contain a MERGE statement. This MERGE statement enables you to accomplish multiple INSERT, UPDATE, and DELETE operations in a single statement.
References: https://docs.microsoft.com/en-us/sql/integration-services/control-flow/merge-in-integration-services-packages
QUESTION 267
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this sections, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a data warehouse that stores information about products, sales, and orders for a manufacturing company. The instance contains a database that has two tables named SalesOrderHeader and SalesOrderDetail. SalesOrderHeader has 500,000 rows and SalesOrderDetail has 3,000,000 rows.
Users report performance degradation when they run the following stored procedure:
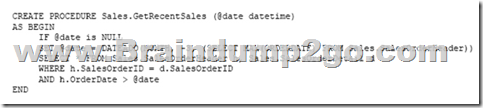
You need to optimize performance.
Solution: You run the following Transact-SQL statement:
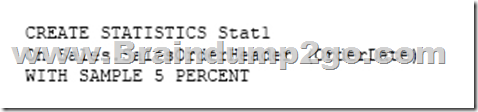
Does the solution meet the goal?
A. Yes
B. No
Answer: B
Explanation:
100 out of 500,000 rows is a too small sample size.
References: https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-tables-statistics
QUESTION 268
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this sections, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are developing a Microsoft SQL Server Integration Services (SSIS) projects. The project consists of several packages that load data warehouse tables.
You need to extend the control flow design for each package to use the following control flow while minimizing development efforts and maintenance:
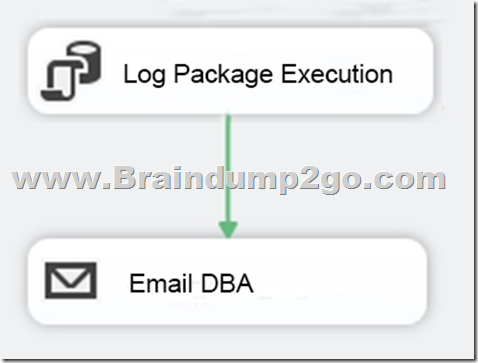
Solution: You add the control flow to a script task. You add an instance of the script task to the storage account in Microsoft Azure.
Does the solution meet the goal?
A. Yes
B. No
Answer: B
Explanation:
A package consists of a control flow and, optionally, one or more data flows.
You create the control flow in a package by using the Control Flow tab in SSIS Designer.
References: https://docs.microsoft.com/en-us/sql/integration-services/control-flow/control-flow
QUESTION 269
Hotspot Question
You are testing a Microsoft SQL Server Integration Services (SSIS) package. The package includes the Control Flow task shown in the Control Flow exhibit (Click the Exhibit button) and the Data Flow task shown in the Data Flow exhibit. (Click the Exhibit button.)
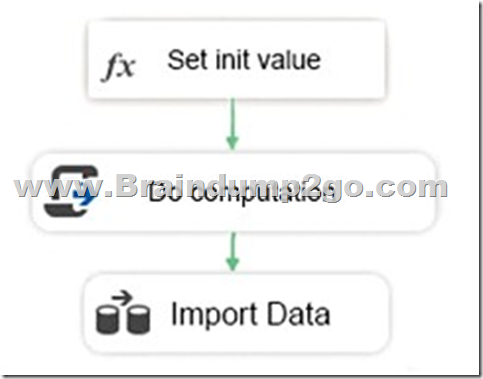
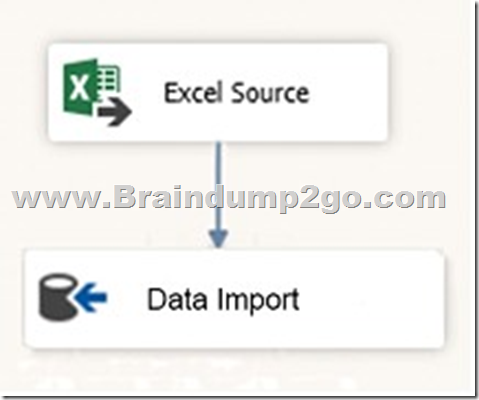
You declare a variable named Seed as shown in the Variables exhibit. (Click the Exhibit button.) The variable is changed by the Script task during execution.
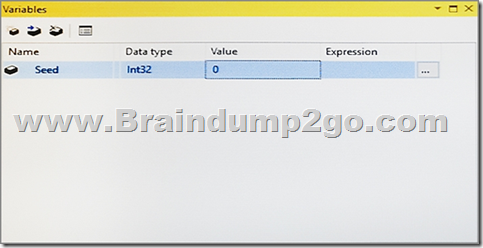
You need to be able to interrogate the value of the Seed variable after the Script task completes execution.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.

Answer:
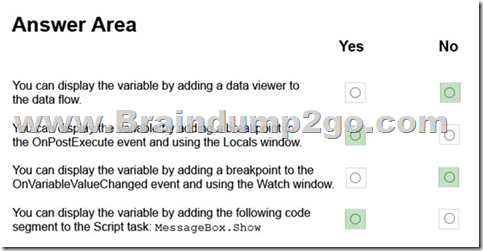
Explanation:
https://docs.microsoft.com/en-us/sql/integration-services/variables-window
!!!RECOMMEND!!!
1.|2018 Latest 70-697 Exam Dumps (PDF & VCE) 287Q&As Download:
https://www.braindump2go.com/70-767.html
2.|2018 Latest 70-697 Study Guide Video:
https://youtu.be/di0FBePt_-w
2018 March New Microsoft 70-697 Exam Dumps with PDF and VCE Free Updated Today! Following are some new 70-697 Real Exam Questions:
1.|2018 Latest 70-697 Exam Dumps (PDF & VCE) 287Q&As Download:
https://www.braindump2go.com/70-767.html
2.|2018 Latest 70-697 Exam Questions & Answers Download:
https://drive.google.com/drive/folders/0B75b5xYLjSSNN1RSdlN6Z0VwRjg?usp=sharing
QUESTION 259
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this sections, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have the following line-of-business solutions:
ERP system
Online WebStore
Partner extranet
One or more Microsoft SQL Server instances support each solution. Each solution has its own product catalog. You have an additional server that hosts SQL Server Integration Services (SSIS) and a data warehouse. You populate the data warehouse with data from each of the line-of-business solutions. The data warehouse does not store primary key values from the individual source tables.
The database for each solution has a table named Products that stored product information. The Products table in each database uses a separate and unique key for product records. Each table shares a column named ReferenceNr between the databases. This column is used to create queries that involve more than once solution.
You need to load data from the individual solutions into the data warehouse nightly. The following requirements must be met:
If a change is made to the ReferenceNr column in any of the sources, set the value of IsDisabled to True and create a new row in the Products table.
If a row is deleted in any of the sources, set the value of IsDisabled to True in the data warehouse.
Solution: Perform the following actions:
Enable the Change Tracking for the Product table in the source databases.
Query the cdc.fn_cdc_get_all_changes_capture_dbo_products function from the sources for updated rows.
Set the IsDisabled column to True for rows with the old ReferenceNr value.
Create a new row in the data warehouse Products table with the new ReferenceNr value.
Does the solution meet the goal?
A. Yes
B. No
Answer: B
Explanation:
We must also handle the deleted rows, not just the updated rows.
References: https://solutioncenter.apexsql.com/enable-use-sql-server-change-data-capture/
QUESTION 260
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this sections, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are developing a Microsoft SQL Server Integration Services (SSIS) projects. The project consists of several packages that load data warehouse tables.
You need to extend the control flow design for each package to use the following control flow while minimizing development efforts and maintenance:
Solution: You add the control flow to an ASP.NET assembly. You add a script task that references this assembly to each data warehouse load package.
Does the solution meet the goal?
A. Yes
B. No
Answer: B
Explanation:
A package consists of a control flow and, optionally, one or more data flows. You create the control flow in a package by using the Control Flow tab in SSIS Designer.
References: https://docs.microsoft.com/en-us/sql/integration-services/control-flow/control-flow
QUESTION 261
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this sections, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a data warehouse that stores information about products, sales, and orders for a manufacturing company. The instance contains a database that has two tables named SalesOrderHeader and SalesOrderDetail. SalesOrderHeader has 500,000 rows and SalesOrderDetail has 3,000,000 rows.
Users report performance degradation when they run the following stored procedure:
You need to optimize performance.
Solution: You run the following Transact-SQL statement:
Does the solution meet the goal?
A. Yes
B. No
Answer: B
Explanation:
Microsoft recommend against specifying 0 PERCENT or 0 ROWS in a CREATE STATISTICS..WITH SAMPLE statement. When 0 PERCENT or ROWS is specified, the statistics object is created but does not contain statistics data.
References: https://docs.microsoft.com/en-us/sql/t-sql/statements/create-statistics-transact-sql
QUESTION 262
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this sections, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are developing a Microsoft SQL Server Integration Services (SSIS) projects. The project consists of several packages that load data warehouse tables.
You need to extend the control flow design for each package to use the following control flow while minimizing development efforts and maintenance:
Solution: You add the control flow to a control flow package part.
You add an instance of the control flow package part to each data warehouse load package.
Does the solution meet the goal?
A. Yes
B. No
Answer: A
Explanation:
A package consists of a control flow and, optionally, one or more data flows.
You create the control flow in a package by using the Control Flow tab in SSIS Designer.
References: https://docs.microsoft.com/en-us/sql/integration-services/control-flow/control-flow
QUESTION 263
You have a data quality project that focuses on the Products catalog for the company. The data includes a product reference number.
The product reference should use the following format:
Two letters followed by an asterisk and then four or five numbers. An example of a valid number is XX*55522.
Any reference number that does not conform to the format must be rejected during the data cleansing.
You need to add a Data Quality Services (DQS) domain rule in the Products domain.
Which rule should you use?
A. value matches pattern ZA*9876[5]
B. value matches pattern AZ[*]1234[5]
C. value matches regular expression AZ[*]1234[5] D. value matches pattern [a-zA-Z][a-zA-Z]*[0-9][0-9] [0-9][0-9] [0-9]?
Answer: A
Explanation:
For a pattern matching rule:
Any letter (A…Z) can be used as a pattern for any letter; case insensitive Any digit (0…9) can be used as a pattern for any digit Any special character, except a letter or a digit, can be used as a pattern for itself Brackets, [], define optional matching
Example: ABC:0000
This rule implies that the data will contain three parts: any three letters followed by a colon
(:), which is again followed by any four digits.
QUESTION 264
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this sections, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Microsoft Azure SQL Data Warehouse instance that must be available six months a day for reporting.
You need to pause the compute resources when the instance is not being used.
Solution: You use SQL Server Management Studio (SSMS).
Does the solution meet the goal?
A. Yes
B. No
Answer: B
Explanation:
To pause a SQL Data Warehouse database, use any of these individual methods.
Pause compute with Azure portal
Pause compute with PowerShell
Pause compute with REST APIs
References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-manage-compute-overview
QUESTION 265
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You are a database administrator for an e-commerce company that runs an online store. The company has the databases described in the following table.
Each day, data from the table OnlineOrder in DB2 must be exported by partition. The tables must not be locked during the process.
You need to write a Microsoft SQL Server Integration Services (SSIS) package that performs the data export.
What should you use?
A. Lookup transformation
B. Merge transformation
C. Merge Join transformation
D. MERGE statement
E. Union All transformation
F. Balanced Data Distributor transformation
G. Sequential container
H. Foreach Loop container
Answer: E
Explanation:
The Union All transformation combines multiple inputs into one output. For example, the outputs from five different Flat File sources can be inputs to the Union All transformation and combined into one output.
References: https://docs.microsoft.com/en-us/sql/integration-services/data-flow/transformations/union-all-transformation
QUESTION 266
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You are a database administrator for an e-commerce company that runs an online store. The company has the databases described in the following table.
Product prices are updated and are stored in a table named Products on DB1. The Products table is deleted and refreshed each night from MDS by using a Microsoft SQL Server Integration Services (SSIS) package. None of the data sources are sorted.
You need to update the SSIS package to add current prices to the Products table.
What should you use?
A. Lookup transformation
B. Merge transformation
C. Merge Join transformation
D. MERGE statement
E. Union All transformation
F. Balanced Data Distributor transformation
G. Sequential container
H. Foreach Loop container
Answer: D
Explanation:
In the current release of SQL Server Integration Services, the SQL statement in an Execute SQL task can contain a MERGE statement. This MERGE statement enables you to accomplish multiple INSERT, UPDATE, and DELETE operations in a single statement.
References: https://docs.microsoft.com/en-us/sql/integration-services/control-flow/merge-in-integration-services-packages
QUESTION 267
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this sections, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a data warehouse that stores information about products, sales, and orders for a manufacturing company. The instance contains a database that has two tables named SalesOrderHeader and SalesOrderDetail. SalesOrderHeader has 500,000 rows and SalesOrderDetail has 3,000,000 rows.
Users report performance degradation when they run the following stored procedure:
You need to optimize performance.
Solution: You run the following Transact-SQL statement:
Does the solution meet the goal?
A. Yes
B. No
Answer: B
Explanation:
100 out of 500,000 rows is a too small sample size.
References: https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-tables-statistics
QUESTION 268
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this sections, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are developing a Microsoft SQL Server Integration Services (SSIS) projects. The project consists of several packages that load data warehouse tables.
You need to extend the control flow design for each package to use the following control flow while minimizing development efforts and maintenance:
Solution: You add the control flow to a script task. You add an instance of the script task to the storage account in Microsoft Azure.
Does the solution meet the goal?
A. Yes
B. No
Answer: B
Explanation:
A package consists of a control flow and, optionally, one or more data flows.
You create the control flow in a package by using the Control Flow tab in SSIS Designer.
References: https://docs.microsoft.com/en-us/sql/integration-services/control-flow/control-flow
QUESTION 269
Hotspot Question
You are testing a Microsoft SQL Server Integration Services (SSIS) package. The package includes the Control Flow task shown in the Control Flow exhibit (Click the Exhibit button) and the Data Flow task shown in the Data Flow exhibit. (Click the Exhibit button.)
You declare a variable named Seed as shown in the Variables exhibit. (Click the Exhibit button.) The variable is changed by the Script task during execution.
You need to be able to interrogate the value of the Seed variable after the Script task completes execution.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
Answer:
Explanation:
https://docs.microsoft.com/en-us/sql/integration-services/variables-window
!!!RECOMMEND!!!
1.|2018 Latest 70-697 Exam Dumps (PDF & VCE) 287Q&As Download:
https://www.braindump2go.com/70-767.html
2.|2018 Latest 70-697 Study Guide Video:
https://youtu.be/di0FBePt_-w
2018 March New Microsoft 70-697 Exam Dumps with PDF and VCE Free Updated Today! Following are some new 70-697 Real Exam Questions:
1.|2018 Latest 70-697 Exam Dumps (PDF & VCE) 287Q&As Download:
https://www.braindump2go.com/70-767.html
2.|2018 Latest 70-697 Exam Questions & Answers Download:
https://drive.google.com/drive/folders/0B75b5xYLjSSNN1RSdlN6Z0VwRjg?usp=sharing
QUESTION 248
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this sections, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Microsoft Azure SQL Data Warehouse instance that must be available six months a day for reporting.
You need to pause the compute resources when the instance is not being used.
Solution: You use the Azure portal.
Does the solution meet the goal?
A. Yes
B. No
Answer: A
QUESTION 249
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have a Microsoft SQL Server data warehouse instance that supports several client applications.
The data warehouse includes the following tables: Dimension.SalesTerritory, Dimension.Customer, Dimension.Date, Fact.Ticket, and Fact.Order.
The Dimension.SalesTerritory and Dimension.Customer tables are frequently updated.
The Fact.Order table is optimized for weekly reporting, but the company wants to change it daily. The Fact.Order table is loaded by using an ETL process. Indexes have been added to the table over time, but the presence of these indexes slows data loading.
All data in the data warehouse is stored on a shared SAN. All tables are in a database named DB1. You have a second database named DB2 that contains copies of production data for a development environment. The data warehouse has grown and the cost of storage has increased. Data older than one year is accessed infrequently and is considered historical.
You have the following requirements:
You are not permitted to make changes to the client applications.
You need to optimize the storage for the data warehouse.
What change should you make?
A. Partition the Fact.Order table, and move historical data to new filegroups on lower-cost storage.
B. Create new tables on lower-cost storage, move the historical data to the new tables, and then shrink the database.
C. Remove the historical data from the database to leave available space for new data.
D. Move historical data to new tables on lower-cost storage.
Answer: A
Explanation:
Create the load staging table in the same filegroup as the partition you are loading. Create the unload staging table in the same filegroup as the partition you are deleteing.
From scenario: Data older than one year is accessed infrequently and is considered historical.
References: https://blogs.msdn.microsoft.com/sqlcat/2013/09/16/top-10-best-practices-for-building-a-large-scale-relational-data-warehouse/
QUESTION 250
You have a Microsoft SQL Server Integration Services (SSIS) package that includes the control flow shown in the following diagram.
You need to choose the enumerator for the Foreach Loop container.
Which enumerator should you use?
A. Foreach SMO Enumerator
B. Foreach Azure Blob Enumerator
C. Foreach NodeList Enumerator
D. Foreach ADO Enumerator
Answer: D
Explanation:
Use the Foreach ADO enumerator to enumerate rows in tables. For example, you can get the rows in an ADO recordset.
QUESTION 251
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this sections, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have the following line-of-business solutions:
ERP system
Online WebStore
Partner extranet
One or more Microsoft SQL Server instances support each solution. Each solution has its own product catalog. You have an additional server that hosts SQL Server Integration Services (SSIS) and a data warehouse. You populate the data warehouse with data from each of the line-of-business solutions. The data warehouse does not store primary key values from the individual source tables.
The database for each solution has a table named Products that stored product information. The Products table in each database uses a separate and unique key for product records. Each table shares a column named ReferenceNr between the databases. This column is used to create queries that involve more than once solution.
You need to load data from the individual solutions into the data warehouse nightly. The following requirements must be met:
If a change is made to the ReferenceNr column in any of the sources, set the value of IsDisabled to True and create a new row in the Products table.
If a row is deleted in any of the sources, set the value of IsDisabled to True in the data warehouse.
Solution: Perform the following actions:
Enable the Change Tracking feature for the Products table in the three source databases.
Query the CHANGETABLE function from the sources for the deleted rows.
Set the IsDIsabled column to True on the data warehouse Products table for the listed rows.
Does the solution meet the goal?
A. Yes
B. No
Answer: B
Explanation:
We must check for updated rows, not just deleted rows.
References: https://www.timmitchell.net/post/2016/01/18/getting-started-with-change-tracking-in-sql-server/
QUESTION 252
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this sections, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a data warehouse that stores information about products, sales, and orders for a manufacturing company. The instance contains a database that has two tables named SalesOrderHeader and SalesOrderDetail. SalesOrderHeader has 500,000 rows and SalesOrderDetail has 3,000,000 rows.
Users report performance degradation when they run the following stored procedure:
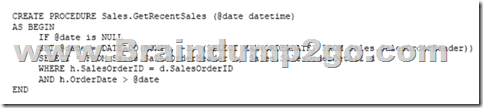
You need to optimize performance.
Solution: You run the following Transact-SQL statement:
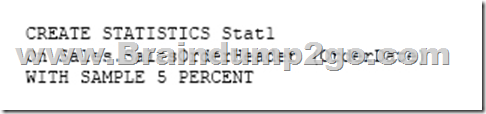
Does the solution meet the goal?
A. Yes
B. No
Answer: A
Explanation:
You can specify the sample size as a percent. A 5% statistics sample size would be helpful.
References: https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-tables-statistics
QUESTION 253
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have a Microsoft SQL Server data warehouse instance that supports several client applications.
The data warehouse includes the following tables: Dimension.SalesTerritory, Dimension.Customer, Dimension.Date, Fact.Ticket, and Fact.Order. The Dimension.SalesTerritory and Dimension.Customer tables are frequently updated. The Fact.Order table is optimized for weekly reporting, but the company wants to change it daily. The Fact.Order table is loaded by using an ETL process. Indexes have been added to the table over time, but the presence of these indexes slows data loading.
All data in the data warehouse is stored on a shared SAN. All tables are in a database named DB1. You have a second database named DB2 that contains copies of production data for a development environment. The data warehouse has grown and the cost of storage has increased. Data older than one year is accessed infrequently and is considered historical.
You have the following requirements:
Implement table partitioning to improve the manageability of the data warehouse and to avoid the need to repopulate all transactional data each night. Use a partitioning strategy that is as granular as possible.
Partition the Fact.Order table and retain a total of seven years of data.
Partition the Fact.Ticket table and retain seven years of data. At the end of each month, the partition structure must apply a sliding window strategy to ensure that a new partition is available for the upcoming month, and that the oldest month of data is archived and removed.
Optimize data loading for the Dimension.SalesTerritory, Dimension.Customer, and Dimension.Date tables.
Incrementally load all tables in the database and ensure that all incremental changes are processed.
Maximize the performance during the data loading process for the Fact.Order partition.
Ensure that historical data remains online and available for querying.
Reduce ongoing storage costs while maintaining query performance for current data.
You are not permitted to make changes to the client applications.
You need to implement the data partitioning strategy.
How should you partition the Fact.Order table?
A. Create 17,520 partitions.
B. Use a granularity of two days.
C. Create 2,557 partitions.
D. Create 730 partitions.
Answer: C
Explanation:
We create on partition for each day. 7 years times 365 days is 2,555. Make that 2,557 to provide for leap years.
From scenario: Partition the Fact.Order table and retain a total of seven years of data. Maximize the performance during the data loading process for the Fact.Order partition.
QUESTION 254
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this sections, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Microsoft Azure SQL Data Warehouse instance that must be available six months a day for reporting.
You need to pause the compute resources when the instance is not being used.
Solution: You use SQL Server Configuration Manager.
Does the solution meet the goal?
A. Yes
B. No
Answer: B
Explanation:
To pause a SQL Data Warehouse database, use any of these individual methods.
Pause compute with Azure portal
Pause compute with PowerShell
Pause compute with REST APIs
References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-manage-compute-overview
QUESTION 255
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You are a database administrator for an e-commerce company that runs an online store.
The company has three databases as described in the following table.

You plan to load at least one million rows of data each night from DB1 into the OnlineOrder table. You must load data into the correct partitions using a parallel process.
You create 24 Data Flow tasks. You must place the tasks into a component to allow parallel load. After all of the load processes compete, the process must proceed to the next task.
You need to load the data for the OnlineOrder table.
What should you use?
A. Lookup transformation
B. Merge transformation
C. Merge Join transformation
D. MERGE statement
E. Union All transformation
F. Balanced Data Distributor transformation
G. Sequential container
H. Foreach Loop container
Answer: H
Explanation:
The Parallel Loop Task is an SSIS Control Flow task, which can execute multiple iterations of the standard Foreach Loop Container concurrently.
References: http://www.cozyroc.com/ssis/parallel-loop-task
QUESTION 256
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You are a database administrator for an e-commerce company that runs an online store.
The company has the databases described in the following table.

Each week, you import a product catalog from a partner company to a staging table in DB2.
You need to create a stored procedure that will update the staging table by inserting new products and deleting discontinued products.
What should you use?
A. Lookup transformation
B. Merge transformation
C. Merge Join transformation
D. MERGE statement
E. Union All transformation
F. Balanced Data Distributor transformation
G. Sequential container
H. Foreach Loop container
Answer: G
QUESTION 257
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this sections, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have the following line-of-business solutions:
ERP system
Online WebStore
Partner extranet
One or more Microsoft SQL Server instances support each solution. Each solution has its own product catalog. You have an additional server that hosts SQL Server Integration Services (SSIS) and a data warehouse. You populate the data warehouse with data from each of the line-of-business solutions. The data warehouse does not store primary key values from the individual source tables.
The database for each solution has a table named Products that stored product information. The Products table in each database uses a separate and unique key for product records. Each table shares a column named ReferenceNr between the databases. This column is used to create queries that involve more than once solution.
You need to load data from the individual solutions into the data warehouse nightly.
The following requirements must be met:
If a change is made to the ReferenceNr column in any of the sources, set the value of IsDisabled to True and create a new row in the Products table.
If a row is deleted in any of the sources, set the value of IsDisabled to True in the data warehouse.
Solution: Perform the following actions:
Enable the Change Tracking for the Product table in the source databases.
Query the CHANGETABLE function from the sources for the updated rows.
Set the IsDisabled column to True for the listed rows that have the old ReferenceNr value.
Create a new row in the data warehouse Products table with the new ReferenceNr value.
Does the solution meet the goal?
A. Yes
B. No
Answer: B
Explanation:
We must check for deleted rows, not just updates rows.
References: https://www.timmitchell.net/post/2016/01/18/getting-started-with-change-tracking-in-sql-server/
QUESTION 258
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You are a database administrator for an e-commerce company that runs an online store. The company has the databases described in the following table.

Each day, you publish a Microsoft Excel workbook that contains a list of product names and current prices to an external website. Suppliers update pricing information in the workbook. Each supplier saves the workbook with a unique name.
Each night, the Products table is deleted and refreshed from MDS by using a Microsoft SQL Server Integration Services (SSIS) package. All files must be loaded in sequence.
You need to add a data flow in an SSIS package to perform the Excel files import in the data warehouse.
What should you use?
A. Lookup transformation
B. Merge transformation
C. Merge Join transformation
D. MERGE statement
E. Union All transformation
F. Balanced Data Distributor transformation
G. Sequential container
H. Foreach Loop container
Answer: A
Explanation:
If you’re familiar with SSIS and don’t want to run the SQL Server Import and Export Wizard, create an SSIS package that uses the Excel Source and the SQL Server Destination in the data flow.
References: https://docs.microsoft.com/en-us/sql/integration-services/import-export-data/import-data-from-excel-to-sql
!!!RECOMMEND!!!
1.|2018 Latest 70-697 Exam Dumps (PDF & VCE) 287Q&As Download:
https://www.braindump2go.com/70-767.html
2.|2018 Latest 70-697 Study Guide Video:
https://youtu.be/di0FBePt_-w